
-
1. 논문 정보
-
2. 연구 목적 (Introduction)
-
연구 배경
-
연구 목표
-
3. 주요 기여 (Contributions)
-
4. 방법론 (Methodology)
-
4.1 RNN 기반 모델
-
4.2 TCN (Temporal Convolutional Network) 모델
-
5. 실험 및 결과 (Experiments & Results)
-
5.1 실험 데이터셋
-
5.2 실험 결과
-
6. 결론 (Conclusion)
-
TCN이 RNN보다 우수한 이유
-
7. 연구의 의의 (Implications)
-
8. 한계점 (Limitations)
-
(1) 데이터 저장량 문제 (Data Storage During Evaluation)
-
(2) 도메인 전이(Transfer Learning)에서의 성능 문제
1. 논문 정보
- 제목: AnEmpirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling
- 저자: shaojie Bai, J. Zico Kolter, Vladlen Koltun
- 소속: Carnegie Mellon University, Intel Labs
- 논문 링크: https://arxiv.org/pdf/1803.01271
2. 연구 목적 (Introduction)
연구 배경
순차 데이터(sequence data)를 다루는 대표적인 방법으로는 RNN(Recurrent Neural Network) 기반 모델(LSTM, GRU 등)이 전통적으로 사용되어 왔음.
이유는 다음과 같다.
- RNN은 과거 정보를 요약하여(hidden state) 현재 예측에 활용하는 구조이므로, 시계열 분석, 자연어 처리(NLP), 음악 생성 등에서 자연스럽게 적용됨.
- LSTM(Long Short-Term Memory) 및 GRU(Gated Recurrent Unit) 과 같은 개선된 RNN 모델은 기존의 RNN이 가진 기울기 소실(Vanishing Gradient) 문제를 해결하여 긴 시퀀스를 다룰 수 있음.
그러나 최근 연구에서 CNN(Convolutional Neural Networks, 합성곱 신경망)이 특정 작업에서 RNN보다 우수한 성능을 보일 수 있음이 보고되었다. 아래의 모델들은 이 논문이 나온 시점에서의 대표적인 CNN 기반 순차 모델이다.
- 대표적인 CNN 기반 순차 모델:
- WaveNet (van den Oord et al., 2016) -> 오디오 합성에서 RNN보다 뛰어난 성능
- ByteNet, ConvS25 (Kalchbrenner et al., 2016; Gehring et al., 2017) -> 기계 번역에서 LSTM보다 우수
- Gated CNN (Dauphin et al., 2017) -> 언어 모델링에서 기존 RNN보다 좋은 성능
하지만, CNN이 RNN을 완전히 대체할 수 있는지에 대한 체계적인 비교 연구는 부족한 상황이었음.
연구 목표
이 논문에서는 위의 질문을 해결하기 위해,
- CNN 기반의 Temporal Convolutional Network(TCN) 모델을 제안하고,
- 기존 RNN(LSTM, GRU)과의 성능 비교를 통해 CNN이 RNN을 대체할 수 있는지 평가하며,
- 다양한 순차 데이터 벤치마크에서 CNN이 RNN보다 뛰어난 성능을 보일 수 있는지 검증하는 것을 목표로 하였다.
3. 주요 기여 (Contributions)
- 순차 데이터 모델링에서 CNN(TCN)과 RNN(LSTM, GRU)의 성능을 체계적으로 비교함.
- TCN 모델을 제안하여 시퀀스 데이터에서의 RNN의 대안으로 활용 가능성을 제시함.
- TCN이 기존 RNN보다 더 긴 기억(Longer Memory)을 유지할 수 있음을 입증함.
- TCN이 병렬 연산이 가능하여 학습 속도가 더 빠름을 실험적으로 증명함.
4. 방법론 (Methodology)
4.1 RNN 기반 모델
RNN 계열 모델은 순차 데이터를 다룰 때 유용하지만, 구조적 한계를 가짐.
(1) RNN (Recurrent Neural Network)
- 기본적인 순환 신경망으로, 과거 데이터를 hidden state로 요약하여 다음 시점으로 전달.
- 그러나 기울기 소실(Vanishing Gradient) 문제로 인해 긴 시퀀스를 학습하는 데 어려움이 있음.
(2) LSTM (Long Short-Term Memory)
- 게이트(Gates) 구조를 도입하여 중요한 정보를 유지하고 불필요한 정보를 삭제하는 방식으로 개선됨.
- 비교적 긴 시퀀스의 정보 유지가 가능하지만, 병렬 연산이 어려워 학습 속도가 느림.
(3) GRU (Gated Recurrent Unit)
- LSTM과 유사하지만, 더 적은 매개변수를 사용하여 학습이 더 효율적임.
- 하지만 장기 의존성 학습(Long-term dependency learning)에서는 한계가 있음.
4.2 TCN (Temporal Convolutional Network) 모델
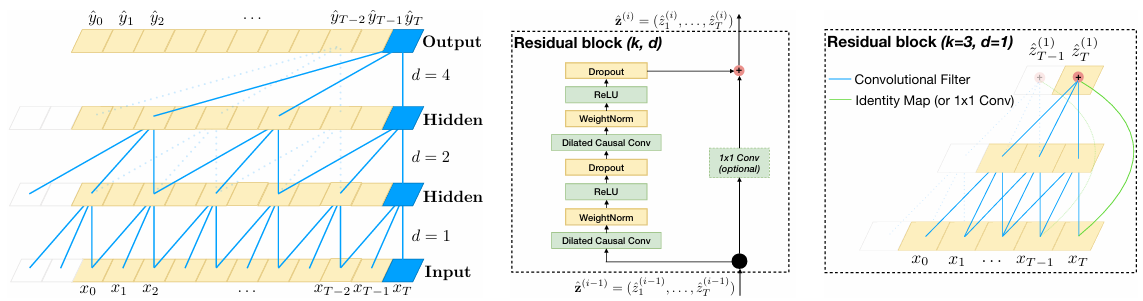
본 논문에서 제안한 Temporal Convolutional Networks (TCN)는 기존 RNN(LSTM, GRU) 기반의 순차 데이터 모델을 대체할 수 있는 CNN 기반의 대안 모델이다. 기존 RNN이 가지는 기억 유지력 문제와 병렬 연산 불가능 문제를 해결하기 위해, TCN은 1D 합성곱(1D Convolution)을 활용하여 시퀀스를 처리한다.
(1) TCN의 핵심 특징
TCN은 기존 CNN과 달리, 순차 데이터 모델링을 위해 특별히 설계된 CNN 구조이다.
TCN의 주요 특징은 다음과 같다.
- Causal Convolutions (인과적 합성곱)
- Dilated Convolutions (확장 합성곱)
- Residual Connections (잔차 연결)
(2) Causal Convolutions (인과적 합성곱)
기존 CNN의 한계
- 일반적인 CNN은 입력 시퀀스를 처리할 때 양방향 정보를 활용한다.
- 하지만, 순차 데이터 모델링에서는 미래 정보를 미리 알고 있으면 안된다.
- 예를 들어, 자연어 처리(NLP)에서 문장을 예측할 때, 아직 등장하지 않은 단어를 참고하면 부자연스러운 것을 확인할 수 있다.
해결 방법
본 논문에서는 시퀀스 데이터 처리 과정에서의 CNN의 한계를 해결하기 위해 인과적 합성곱(Causal Convolutions)을 제안하였다.
- TCN은 미래 정보를 보지 않도록 인과적 합성곱(Casual Convolution)을 사용한다.
- 즉, 각 시점 t에서 예측을 할 때, t 이전의 입력값들만을 사용하여 출력을 생성한다.
- 이를 위해 CNN의 필터가 미래 정보를 참조하지 않도록 특수한 패딩(Zero Padding)을 추가하여 길이를 맞춘다.
수식
$$y_t = \displaystyle\sum_{i=0}^{k-1}{w_ix_{t-i}}$$
- \(y_t\) : t 시점에서의 출력
- \(w_i\) : CNN 필터 가중치
- \(x_{t-i}\) : t 이전의 입력값
=> t 이후의 값(\(x_{t+1}, x_{t+2}\) 등)은 포함되지 않음.
예시
입력 시퀀스가 [x0, x1, x2, x3, x4, x5]이고, 출력 예측이 [y0, y1, y2, y3, y4, y5]일 때,
- 일반적인 CNN에서는 y3을 예측할 때 x4, x5도 활용할 수 있지만,
- TCN에서는 y3을 예측할 때 x0 ~ x3 만 참고 가능하다.
(3) Dilated Convolutions
기존 RNN의 한계: 단기 기억 소실 문제
- RNN은 시간 순서대로 한 단계씩 정보가 전달되기 때문에, 과거 정보를 장기적으로 유지하기 어렵다.
- LSTM/GRU는 단기 기억 소실 문제가 어느정도 개선되었지만, 긴 시퀀스를 다룰 때는 여전히 한계가 존재한다.
해결 방법: Dilated Convolutions (확장 합성곱)
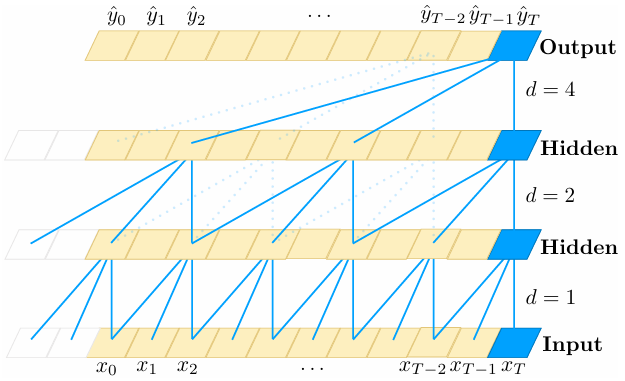
본 논문에서는 기존 RNN 모델에서 발생하는 단기 기억 소실 문제를 해결하기 위해 확장 합성곱(Dilated Convolutions)을 제안하였다. 확장 합성곱에 대한 자세한 설명은 링크에서 확인 가능합니다.
- TCN은 Dilated Convolutions(확장 합성곱)을 사용하여 더 먼 과거 정보를 효과적으로 학습할 수 있다.
- Dilated Convolution은 합성곱 필터가 입력 시퀀스를 일정 간격(dilation factor)으로 건너뛰면서 적용된다.
- 이를 통해 필터 크기가 커지지 않더라도, 과거의 정보를 넓은 범위에서 참조 가능하다.
수식
$$F(s) = (x*_{d} f)(s) = \sum_{i=0}^{k-1} f(i) \cdot x_{s - d \cdot i} $$
- \(d\) : Dilation Factor (확장 계수)
- \(k\) : CNN 필터 크기
=> \(d\)를 증가시키면 더 먼 과거까지 정보를 참고 가능.
(4) Residual Connections (잔차 연결, Skip Connections)
깊은 신경망의 문제점: 기울기 소실
- TCN이 충분히 깊어지면, 기울기 소실(Vanishing Gradient) 문제가 발생할 수 있다.
- 즉, 네트워크가 싶어질수록 초기 층이 제대로 학습되지 않는다.
해결 방법: Residual Connections
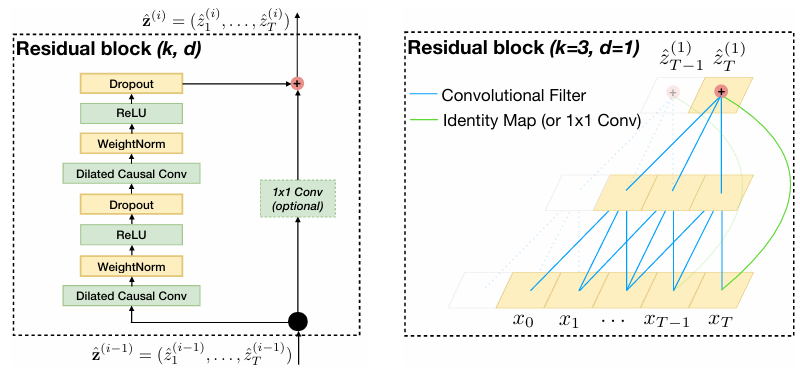
본 논문에서는 깊은 신경망에서 발생할 수 있는 기울기 소실 문제를 해결하기 위해 TCN 모델에 Residual Connection을 적용하였다.
- ResNet과 유사한 잔차 연결(Resudual Connections)을 추가하여, 기울기 소실 문제를 방지한다.
- 기존 출력값에 입력값을 직접 더하는 구조(Identity Mapping)를 사용하여 안정적인 학습이 가능하다.
수식
$$ o = Activation(x + F(x))$$
- \(x\) : 원래 입력값
- \(F(x)\) : 합성곱을 통과한 후 결과
=> 레이어를 거치면서 소실된 정보를 학습할 수 있도록 도와준다.
5. 실험 및 결과 (Experiments & Results)
본 논문에서는 제안한 TCN 모델과 RNN(LSTM, GRU) 계열의 모델 성능을 다양한 데이터셋에서 비교하였다.
5.1 실험 데이터셋
- Synthetic Stress Tests
- Adding Problem (장기 기억 유지력 테스트)
- Copy Memory Task (정보 보존력 테스트)
- MNIST 및 변형된 P-MNIST
- 순차적인 픽셀 데이터를 처리하는 능력 평가
- 음악 데이터
- JSB Chorales, Nottingham Dataset
- 자연어 처리 (NLP) 데이터
- PennTreebank (PTB)
- WikiText-103
- LAMBADA (긴 문맥 이해력 테스트)
5.2 실험 결과
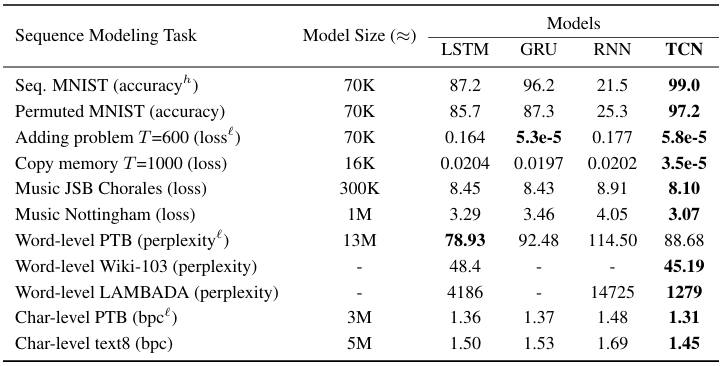
- TCN이 모든 실험에서 RNN(LSTM, GRU)보다 더 우수한 성능을 보였다.
- 특히, 기억 유지력이 중요한 실험(Adding Problem, Copy Memory)에서 압도적인 성능차이를 보였다.
- MNIST 실험에서도 TCN이 RNN보다 높은 정확도를 기록하였다.
=> 위 실험을 통해TCN은 병렬 연산 덕분에 더 빠르게 학습 가능하며, RNN보다 더 긴 의존성을 학습할 수 있음을 입증하였다.
6. 결론 (Conclusion)
본 연구는 순차 데이터 모델링에서 기존의 RNN(LSTM, GRU)이 필수적인 선택지가 아닐 수 있음을 실험적으로 입증했다. 기존 연구들은 주로 순차 데이터 분석에는 RNN이 최적이라는 가정을 따랐으나, 본 연구에서는 CNN 기반의 Temporal Convolutional Network (TCN)이 RNN보다 더 긴 기억(Longer Memory)을 유지할 수 있으며, 학습 속도와 병렬 처리에서 큰 이점을 가짐을 보였다.
TCN이 RNN보다 우수한 이유
(1) 더 긴 기억 유지 가능 -> 장기 의존성(Long-Term Dependency) 학습에 유리
- RNN은 기울기 소실(Vanishing Gradient) 문제로 인해 먼 과거의 정보를 학습하기 어려운 반면,
- TCN은 Dilated Convolutions를 통해 먼 과거 정보까지 효과적으로 참조 가능.
(2) 병렬 연산 가능 -> RNN보다 학습 속도가 빠름
- RNN은 순차적인(time-step-wise) 계산 방식으로 인해 병렬 연산이 불가능하지만,
- TCN은 CNN 기반 모델이므로, 전체 시퀀스를 병렬로 처리 가능하다. -> 학습 속도가 크게 향상.
(3) 순차 데이터 모델링에서 CNN이 강력한 대안이 될 수 있음을 증명
- 기존 RNN 기반 접근법이 필수적이라는 가정을 깨고,
- 다양한 벤치마크 실험(언어 모델링, 음악 생성, 시계열 분석)에서 TCN이 RNN보다 우수한 성능을 보임을 입증.
7. 연구의 의의 (Implications)
본 연구는 순차 데이터 모델링에서 CNN 기반 접근법이 유효한 대안이 될 수 있음을 입증한 중요한 연구이다. 특히, 병렬 연산이 가능한 TCN이 더 긴 기억을 유지할 수 있음을 실험적으로 보이며, RNN이 순차 데이터 모델링의 유일한 선택지가 아닐 수 있음을 제시했다. 이 연구는 NLP, 시계열 분석, 음성 처리 등 다양한 분야에서 CNN 기반 모델을 적용할 필요성을 제기하며, 향후 연구에서 더 발전될 가능성을 열어준다.
8. 한계점 (Limitations)
본 연구는 CNN 기반의 TCN(Temporal Convolutional Networks)이 RNN(LSTM, GRU)보다 순차 데이터 모델링에서 뛰어난 성능을 보일 수 있음을 실험적으로 입증했다. 하지만, 다음과 같은 한계점이 존재한다.
(1) 데이터 저장량 문제 (Data Storage During Evaluation)
- RNN은 입력 시퀀스를 처리할 때 hidden state만 유지하면 되므로, 과거 데이터를 직접 저장할 필요가 없다.
- 반면, TCN은 입력 시퀀스를 ConvNet 필터를 통해 처리하므로, 출력을 생성할 때 모든 과거 입력 데이터를 유지해야 한다. -> 메모리 사용량 증가 가능성.
(2) 도메인 전이(Transfer Learning)에서의 성능 문제
- TCN은 특정 도메인(언어 모델링, 시계열 분석 등)에서는 뛰어난 성능을 보였지만, 도메인 간 전이(Transfer Learning)에 대한 연구가 부족하다.
- 예를 들어, TCN이 자연어 처리(NLP)에서 좋은 성능을 보였다고 해서, 금융 데이터나 의료 데이터에서도 동일한 성능을 보장할 수 없다.
'논문 리뷰' 카테고리의 다른 글
| 논문 리뷰: A Time Series Is Worth 64 Words: Long-Term Forecasting With Transformers (2) | 2025.03.26 |
|---|---|
| 논문 리뷰: Attention Is All You Need (1) | 2025.03.19 |
1. 논문 정보
- 제목: AnEmpirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling
- 저자: shaojie Bai, J. Zico Kolter, Vladlen Koltun
- 소속: Carnegie Mellon University, Intel Labs
- 논문 링크: https://arxiv.org/pdf/1803.01271
2. 연구 목적 (Introduction)
연구 배경
순차 데이터(sequence data)를 다루는 대표적인 방법으로는 RNN(Recurrent Neural Network) 기반 모델(LSTM, GRU 등)이 전통적으로 사용되어 왔음.
이유는 다음과 같다.
- RNN은 과거 정보를 요약하여(hidden state) 현재 예측에 활용하는 구조이므로, 시계열 분석, 자연어 처리(NLP), 음악 생성 등에서 자연스럽게 적용됨.
- LSTM(Long Short-Term Memory) 및 GRU(Gated Recurrent Unit) 과 같은 개선된 RNN 모델은 기존의 RNN이 가진 기울기 소실(Vanishing Gradient) 문제를 해결하여 긴 시퀀스를 다룰 수 있음.
그러나 최근 연구에서 CNN(Convolutional Neural Networks, 합성곱 신경망)이 특정 작업에서 RNN보다 우수한 성능을 보일 수 있음이 보고되었다. 아래의 모델들은 이 논문이 나온 시점에서의 대표적인 CNN 기반 순차 모델이다.
- 대표적인 CNN 기반 순차 모델:
- WaveNet (van den Oord et al., 2016) -> 오디오 합성에서 RNN보다 뛰어난 성능
- ByteNet, ConvS25 (Kalchbrenner et al., 2016; Gehring et al., 2017) -> 기계 번역에서 LSTM보다 우수
- Gated CNN (Dauphin et al., 2017) -> 언어 모델링에서 기존 RNN보다 좋은 성능
하지만, CNN이 RNN을 완전히 대체할 수 있는지에 대한 체계적인 비교 연구는 부족한 상황이었음.
연구 목표
이 논문에서는 위의 질문을 해결하기 위해,
- CNN 기반의 Temporal Convolutional Network(TCN) 모델을 제안하고,
- 기존 RNN(LSTM, GRU)과의 성능 비교를 통해 CNN이 RNN을 대체할 수 있는지 평가하며,
- 다양한 순차 데이터 벤치마크에서 CNN이 RNN보다 뛰어난 성능을 보일 수 있는지 검증하는 것을 목표로 하였다.
3. 주요 기여 (Contributions)
- 순차 데이터 모델링에서 CNN(TCN)과 RNN(LSTM, GRU)의 성능을 체계적으로 비교함.
- TCN 모델을 제안하여 시퀀스 데이터에서의 RNN의 대안으로 활용 가능성을 제시함.
- TCN이 기존 RNN보다 더 긴 기억(Longer Memory)을 유지할 수 있음을 입증함.
- TCN이 병렬 연산이 가능하여 학습 속도가 더 빠름을 실험적으로 증명함.
4. 방법론 (Methodology)
4.1 RNN 기반 모델
RNN 계열 모델은 순차 데이터를 다룰 때 유용하지만, 구조적 한계를 가짐.
(1) RNN (Recurrent Neural Network)
- 기본적인 순환 신경망으로, 과거 데이터를 hidden state로 요약하여 다음 시점으로 전달.
- 그러나 기울기 소실(Vanishing Gradient) 문제로 인해 긴 시퀀스를 학습하는 데 어려움이 있음.
(2) LSTM (Long Short-Term Memory)
- 게이트(Gates) 구조를 도입하여 중요한 정보를 유지하고 불필요한 정보를 삭제하는 방식으로 개선됨.
- 비교적 긴 시퀀스의 정보 유지가 가능하지만, 병렬 연산이 어려워 학습 속도가 느림.
(3) GRU (Gated Recurrent Unit)
- LSTM과 유사하지만, 더 적은 매개변수를 사용하여 학습이 더 효율적임.
- 하지만 장기 의존성 학습(Long-term dependency learning)에서는 한계가 있음.
4.2 TCN (Temporal Convolutional Network) 모델
본 논문에서 제안한 Temporal Convolutional Networks (TCN)는 기존 RNN(LSTM, GRU) 기반의 순차 데이터 모델을 대체할 수 있는 CNN 기반의 대안 모델이다. 기존 RNN이 가지는 기억 유지력 문제와 병렬 연산 불가능 문제를 해결하기 위해, TCN은 1D 합성곱(1D Convolution)을 활용하여 시퀀스를 처리한다.
(1) TCN의 핵심 특징
TCN은 기존 CNN과 달리, 순차 데이터 모델링을 위해 특별히 설계된 CNN 구조이다.
TCN의 주요 특징은 다음과 같다.
- Causal Convolutions (인과적 합성곱)
- Dilated Convolutions (확장 합성곱)
- Residual Connections (잔차 연결)
(2) Causal Convolutions (인과적 합성곱)
기존 CNN의 한계
- 일반적인 CNN은 입력 시퀀스를 처리할 때 양방향 정보를 활용한다.
- 하지만, 순차 데이터 모델링에서는 미래 정보를 미리 알고 있으면 안된다.
- 예를 들어, 자연어 처리(NLP)에서 문장을 예측할 때, 아직 등장하지 않은 단어를 참고하면 부자연스러운 것을 확인할 수 있다.
해결 방법
본 논문에서는 시퀀스 데이터 처리 과정에서의 CNN의 한계를 해결하기 위해 인과적 합성곱(Causal Convolutions)을 제안하였다.
- TCN은 미래 정보를 보지 않도록 인과적 합성곱(Casual Convolution)을 사용한다.
- 즉, 각 시점 t에서 예측을 할 때, t 이전의 입력값들만을 사용하여 출력을 생성한다.
- 이를 위해 CNN의 필터가 미래 정보를 참조하지 않도록 특수한 패딩(Zero Padding)을 추가하여 길이를 맞춘다.
수식
=> t 이후의 값(
예시
입력 시퀀스가 [x0, x1, x2, x3, x4, x5]이고, 출력 예측이 [y0, y1, y2, y3, y4, y5]일 때,
- 일반적인 CNN에서는 y3을 예측할 때 x4, x5도 활용할 수 있지만,
- TCN에서는 y3을 예측할 때 x0 ~ x3 만 참고 가능하다.
(3) Dilated Convolutions
기존 RNN의 한계: 단기 기억 소실 문제
- RNN은 시간 순서대로 한 단계씩 정보가 전달되기 때문에, 과거 정보를 장기적으로 유지하기 어렵다.
- LSTM/GRU는 단기 기억 소실 문제가 어느정도 개선되었지만, 긴 시퀀스를 다룰 때는 여전히 한계가 존재한다.
해결 방법: Dilated Convolutions (확장 합성곱)
본 논문에서는 기존 RNN 모델에서 발생하는 단기 기억 소실 문제를 해결하기 위해 확장 합성곱(Dilated Convolutions)을 제안하였다. 확장 합성곱에 대한 자세한 설명은 링크에서 확인 가능합니다.
- TCN은 Dilated Convolutions(확장 합성곱)을 사용하여 더 먼 과거 정보를 효과적으로 학습할 수 있다.
- Dilated Convolution은 합성곱 필터가 입력 시퀀스를 일정 간격(dilation factor)으로 건너뛰면서 적용된다.
- 이를 통해 필터 크기가 커지지 않더라도, 과거의 정보를 넓은 범위에서 참조 가능하다.
수식
=>
(4) Residual Connections (잔차 연결, Skip Connections)
깊은 신경망의 문제점: 기울기 소실
- TCN이 충분히 깊어지면, 기울기 소실(Vanishing Gradient) 문제가 발생할 수 있다.
- 즉, 네트워크가 싶어질수록 초기 층이 제대로 학습되지 않는다.
해결 방법: Residual Connections
본 논문에서는 깊은 신경망에서 발생할 수 있는 기울기 소실 문제를 해결하기 위해 TCN 모델에 Residual Connection을 적용하였다.
- ResNet과 유사한 잔차 연결(Resudual Connections)을 추가하여, 기울기 소실 문제를 방지한다.
- 기존 출력값에 입력값을 직접 더하는 구조(Identity Mapping)를 사용하여 안정적인 학습이 가능하다.
수식
=> 레이어를 거치면서 소실된 정보를 학습할 수 있도록 도와준다.
5. 실험 및 결과 (Experiments & Results)
본 논문에서는 제안한 TCN 모델과 RNN(LSTM, GRU) 계열의 모델 성능을 다양한 데이터셋에서 비교하였다.
5.1 실험 데이터셋
- Synthetic Stress Tests
- Adding Problem (장기 기억 유지력 테스트)
- Copy Memory Task (정보 보존력 테스트)
- MNIST 및 변형된 P-MNIST
- 순차적인 픽셀 데이터를 처리하는 능력 평가
- 음악 데이터
- JSB Chorales, Nottingham Dataset
- 자연어 처리 (NLP) 데이터
- PennTreebank (PTB)
- WikiText-103
- LAMBADA (긴 문맥 이해력 테스트)
5.2 실험 결과
- TCN이 모든 실험에서 RNN(LSTM, GRU)보다 더 우수한 성능을 보였다.
- 특히, 기억 유지력이 중요한 실험(Adding Problem, Copy Memory)에서 압도적인 성능차이를 보였다.
- MNIST 실험에서도 TCN이 RNN보다 높은 정확도를 기록하였다.
=> 위 실험을 통해TCN은 병렬 연산 덕분에 더 빠르게 학습 가능하며, RNN보다 더 긴 의존성을 학습할 수 있음을 입증하였다.
6. 결론 (Conclusion)
본 연구는 순차 데이터 모델링에서 기존의 RNN(LSTM, GRU)이 필수적인 선택지가 아닐 수 있음을 실험적으로 입증했다. 기존 연구들은 주로 순차 데이터 분석에는 RNN이 최적이라는 가정을 따랐으나, 본 연구에서는 CNN 기반의 Temporal Convolutional Network (TCN)이 RNN보다 더 긴 기억(Longer Memory)을 유지할 수 있으며, 학습 속도와 병렬 처리에서 큰 이점을 가짐을 보였다.
TCN이 RNN보다 우수한 이유
(1) 더 긴 기억 유지 가능 -> 장기 의존성(Long-Term Dependency) 학습에 유리
- RNN은 기울기 소실(Vanishing Gradient) 문제로 인해 먼 과거의 정보를 학습하기 어려운 반면,
- TCN은 Dilated Convolutions를 통해 먼 과거 정보까지 효과적으로 참조 가능.
(2) 병렬 연산 가능 -> RNN보다 학습 속도가 빠름
- RNN은 순차적인(time-step-wise) 계산 방식으로 인해 병렬 연산이 불가능하지만,
- TCN은 CNN 기반 모델이므로, 전체 시퀀스를 병렬로 처리 가능하다. -> 학습 속도가 크게 향상.
(3) 순차 데이터 모델링에서 CNN이 강력한 대안이 될 수 있음을 증명
- 기존 RNN 기반 접근법이 필수적이라는 가정을 깨고,
- 다양한 벤치마크 실험(언어 모델링, 음악 생성, 시계열 분석)에서 TCN이 RNN보다 우수한 성능을 보임을 입증.
7. 연구의 의의 (Implications)
본 연구는 순차 데이터 모델링에서 CNN 기반 접근법이 유효한 대안이 될 수 있음을 입증한 중요한 연구이다. 특히, 병렬 연산이 가능한 TCN이 더 긴 기억을 유지할 수 있음을 실험적으로 보이며, RNN이 순차 데이터 모델링의 유일한 선택지가 아닐 수 있음을 제시했다. 이 연구는 NLP, 시계열 분석, 음성 처리 등 다양한 분야에서 CNN 기반 모델을 적용할 필요성을 제기하며, 향후 연구에서 더 발전될 가능성을 열어준다.
8. 한계점 (Limitations)
본 연구는 CNN 기반의 TCN(Temporal Convolutional Networks)이 RNN(LSTM, GRU)보다 순차 데이터 모델링에서 뛰어난 성능을 보일 수 있음을 실험적으로 입증했다. 하지만, 다음과 같은 한계점이 존재한다.
(1) 데이터 저장량 문제 (Data Storage During Evaluation)
- RNN은 입력 시퀀스를 처리할 때 hidden state만 유지하면 되므로, 과거 데이터를 직접 저장할 필요가 없다.
- 반면, TCN은 입력 시퀀스를 ConvNet 필터를 통해 처리하므로, 출력을 생성할 때 모든 과거 입력 데이터를 유지해야 한다. -> 메모리 사용량 증가 가능성.
(2) 도메인 전이(Transfer Learning)에서의 성능 문제
- TCN은 특정 도메인(언어 모델링, 시계열 분석 등)에서는 뛰어난 성능을 보였지만, 도메인 간 전이(Transfer Learning)에 대한 연구가 부족하다.
- 예를 들어, TCN이 자연어 처리(NLP)에서 좋은 성능을 보였다고 해서, 금융 데이터나 의료 데이터에서도 동일한 성능을 보장할 수 없다.
'논문 리뷰' 카테고리의 다른 글
| 논문 리뷰: A Time Series Is Worth 64 Words: Long-Term Forecasting With Transformers (2) | 2025.03.26 |
|---|---|
| 논문 리뷰: Attention Is All You Need (1) | 2025.03.19 |