
반응형
1. 데이터 전처리란?
데이터 전처리는 분석이나 모델링을 위해 데이터를 정제하고 변환하는 과정이다. 데이터는 수집 단계에서 결측치, 이상치, 다양한 형식의 값 등을 포함할 수 있으므로, 이를 적절히 처리해야 분석 및 모델 성능을 높일 수 있다.
2. 데이터 전처리 순서
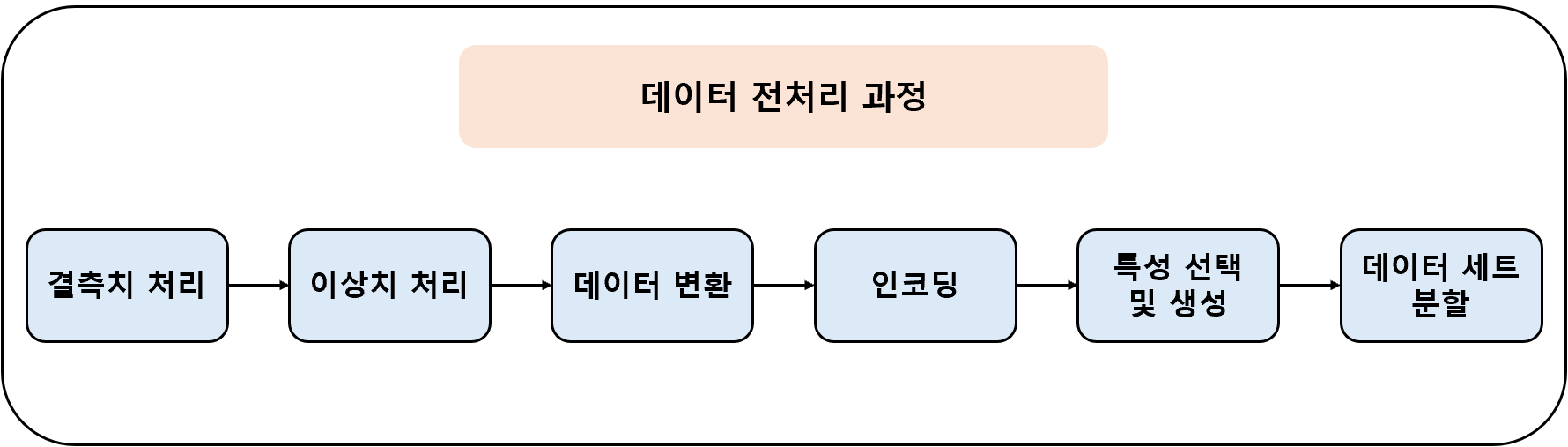
데이터 전처리는 일반적으로 위 그림과 같은 순서로 진행된다.
- 결측치 처리: 누락된 데이터를 제거하거나 적절한 값으로 대체
- 이상치 처리: 통계적 방법으로 이상값을 탐지하고 제거 또는 수정
- 데이터 변환: 로그 변환, 스케일링, 정규화 등을 수행
- 인코딩: 범주형 변수를 숫자로 변환
- 특성 선택 및 생성: 중요한 변수를 선택하거나 새로운 변수를 생성
- 데이터 세트 분할: 훈련, 검증, 테스트 세트로 분할
3. 결측치 처리 (Missing Value Handling)
결측치(Missing values)는 분석 정확도를 낮출 수 있기 때문에 처리 필요
(1) 결측치 확인
- 데이터 내에서 각 열의 결측값 개수를 파악하여 결측 여부와 심각성 판단
df.isnull().sum()
(2) 결측치 제거
- 결측값이 포함된 행이나 열을 제거하여 데이터 손실 가능성 고려
df.dropna(inplace=True)
(3) 결측치 대체 (Imputation)
- 결측값을 특정 통계값(평균, 중위수 등)으로 대체하여 데이터 유지
df['변수명'].fillna(df['변수명'].mean(), inplace=True) # 평균값으로 대체
(4) 보간(Interpolation)
- 주변 데이터 값들로 결측치를 추정하여 자연스럽게 결측값을 채움
df['변수명'].interpolate(method='linear', inplace=True) # 선형 보간 이용
4. 이상치 처리 (Outlier Handling)
이상치(Outliers)는 비정상적이거나 분석 결과에 왜곡을 유발할 수 있는 데이터를 의미한다.
(1) Z-score를 이용한 이상치 탐지
- 데이터 포인트가 평균에서 얼마나 떨어져 있는지를 표준편차 단위로 표현하여 이상치를 탐지
from scipy import stats
import numpy as np
z_scores = np.abs(stats.zscore(df))
outliers = (z_scores > threshold).all(axis=1)
# 이상치 제거
df = df[~outliers]
(2) IQR (사분위 범위) 방법
- 데이터를 사분위수로 나누어 이상치를 식별하는 방법으로 데이터 분포에 민감하지 않음
Q1 = df['values'].quantile(0.25)
Q3 = df['values'].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = df[(df['values'] < lower_bound) | (df['values'] > upper_bound)]
df = df[~outliers]
5. 데이터 변환 (Data Transformation)
데이터 변환은 특성 간의 범위를 조절하고 모델의 학습 속도 및 정확도를 향상시킨다.
(1) 정규화(Normalization)
- 데이터 값을 0~1 범위로 조정
- 예시: Min-Max Scaling
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
df['스케일링변수'] = scaler.fit_transform(df[['원본변수']])
(2) 표준화(Standardization)
- 평균이 0이고 표준편차가 1인 표준 정규분포 형태로 데이터를 변환
- 예시: Standard Scaling
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df['스케일링변수'] = scaler.fit_transform(df[['원본변수']])
(3) 로그 변환(Log Transformation)
- 비대칭 분포(왜도가 큰 데이터)의 특성을 정규분포에 가깝게 조정
df['로그변환'] = np.log(df['원본변수'])
(4) 자료형 변환
- 데이터를 적합한 형태로 변경하여 분석이나 모델 학습의 정확성을 높임
# 정수형 변환
df['column_name'] = df['column_name'].astype(int)
# 부동 소수점 변환
df['column_name'] = df['column_name'].astype(float)
# 문자열 변환
df['column_name'] = df['column_name'].astype(str)
# 카테고리형 변환
df['column_name'] = df['column_name'].astype('category')
# 날짜형 변환
df['date_column'] = pd.to_datetime(df['date_column'])
6. 인코딩(Encoding)
범주형 데이터를 숫자형으로 변환하여 머신러닝 알고리즘을 적용 가능하게 한다.
(1) 원-핫 인코딩(One-Hot Encoding)
- 범주형 변수를 이진 변수로 변환하여 변수 간 서열 관계가 없음을 명확히 나타낸다.
df_encoded = pd.get_dummies(df, columns=['범주형변수'])
(2) 레이블 인코딩(Label Encoding)
- 범주형 변수의 값에 숫자를 할당하여 서열 관계를 표현할 때 유용하다.
from sklearn.preprocessing import LabelEncoder
label_encoder = LabelEncoder()
df['범주형변수'] = label_encoder.fit_transform(df['범주형변수'])
7. 특성 선택 및 생성
분석이나 모델링 시 변수의 중요성을 판단하고, 필요한 변수를 추가하거나 불필요한 변수를 제거
(1) 중요 특성 선택 (예시: Feature Importance 활용)
- 모델의 성능을 높이기 위해 영향력이 높은 특성만 선택
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
model.fit(X, y)
importance = model.feature_importances_
selected_features = X.columns[importance > threshold]
(2) 새로운 특성 생성
- 기존 특성들을 결합하여 모델에 유의미한 정보를 제공할 수 있는 새로운 특성을 생성
df['새로운변수'] = df['기존변수1'] * df['기존변수2']
8. 데이터 세트 분할
- 모델의 정확한 성능 평가를 위해 데이터를 훈련, 검증, 테스트 세트로 분할
from sklearn.model_selection import train_test_split
X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size=0.3, random_state=42)
X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, random_state=42)
반응형
LIST
'데이터 분석' 카테고리의 다른 글
| PCA (주성분 분석, Principal Component Analysis) (0) | 2025.03.19 |
|---|---|
| 탐색적 데이터 분석 (EDA : Exploratory Data Analysis) (0) | 2025.03.10 |
| 범주형 데이터 처리 (0) | 2025.03.10 |
| 특징 선택(Feature Selection) (0) | 2025.03.10 |
| 표준화(Standardization)와 정규화(Normalization) (0) | 2025.03.09 |